1.1. Choosing the right metric#
Empulse provides a variety of metrics to evaluate the performance of a model. Choosing the right metric is crucial to gauge the performance of your model in the real world. Before choosing a metric, it is important to understand the problem you are trying to solve and the business context. Value and cost-sensitive metrics are particularly useful when the costs and benefits of different outcomes are not equal. To quantify the consequences of different outcomes, both streams of literature use a cost matrix (or cost-benefit matrix).
1.1.1. Cost Matrix#
The cost matrix is a square matrix where the rows represent the predicted class and the columns represent the true class. Each element of the matrix represents the cost associated with the corresponding pair of predicted and true classes.
Actual positive \(y_i = 1\) |
Actual negative \(y_i = 0\) |
|
Predicted positive \(\hat{y}_i = 1\) |
\(C(1|1)\) |
\(C(1|0)\) |
Predicted negative \(\hat{y}_i = 0\) |
\(C(0|1)\) |
\(C(0|0)\) |
All value-driven and cost-sensitive metrics are derived from the cost matrix.
Empulse represents these costs as tp_cost, fp_cost, fn_cost, and tn_cost,
for true positive, false positive, false negative, and true negative costs, respectively.
So if you want to indicate that making a false positive prediction is 5 times more costly than making a false negative prediction, you can set the costs as follows:
tp_cost = 0
fp_cost = 5
fn_cost = 1
tn_cost = 0
An important side note is that in value-driven metrics, the cost of correctly classifying is seen as a benefit. Therefore, the cost matrix is often referred to as a cost-benefit matrix in this context. Concretely, this just means that a value-driven cost-benefit matrix just takes the negative of the true positive and true negative costs.
Actual positive \(y_i = 1\) |
Actual negative \(y_i = 0\) |
|
Predicted positive \(\hat{y}_i = 1\) |
\(b_0 = -C(1|1)\) |
\(c_0 = C(1|0)\) |
Predicted negative \(\hat{y}_i = 0\) |
\(c_1 = C(0|1)\) |
\(b_1 = -C(0|0)\) |
For value-driven metrics,
Empulse represents the cost and benefits as tp_benefit, fp_cost, fn_cost, and tn_benefit,
for true positive, false positive, false negative, and true negative benefits, respectively.
So if you want to indicate that making a true positive prediction is 5 times more beneficial than making a true negative prediction, you can set the costs as follows:
tp_benefit = 5
fp_cost = 0
fn_cost = 0
tn_benefit = 1
1.1.2. Example Cost-Benefit Matrix#
The best way to understand the cost matrix is through an example. Consider a binary classification problem where the goal is to predict whether a customer is going to churn in the next year.
We presumes a situation where predicted churners are contacted and offered an incentive to remain customers. Only a fraction of churners accepts the incentive offer (the accept rate). If a churner accepts the incentive, the company wins back the customer and receives the customer’s lifetime value. If a loyal customer is offered an incentive, they will happily accept it, since they were going to stay anyway. In both situations, the company incurs a cost for contacting the customer and the cost of the incentive. If a churner declines the incentive, the company still incurs the cost of contacting the customer.
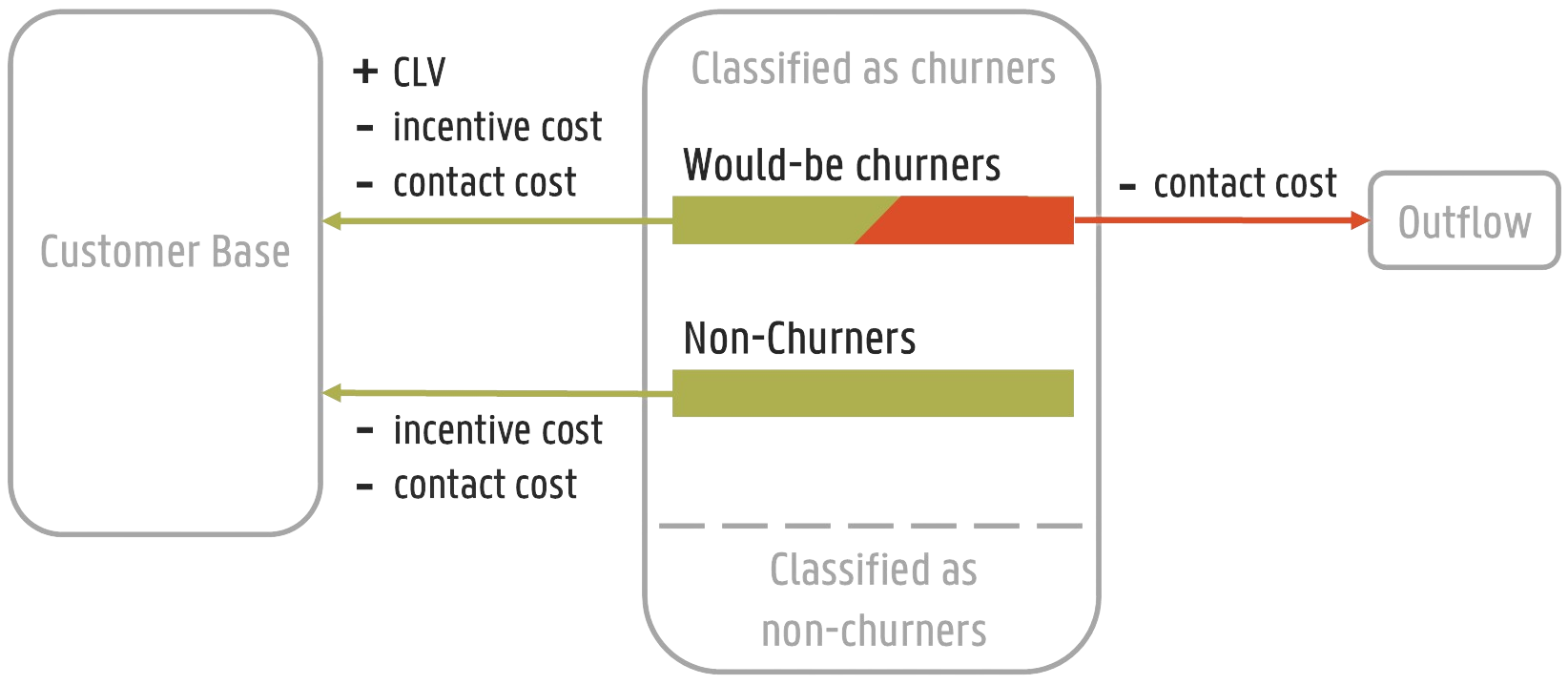
The cost-benefit matrix for this example is shown in the figure above.
accepts rate: \(\gamma\)
customer lifetime value: \(CLV\)
cost of contacting the customer: \(c\)
cost of the incentive: \(d\)
Actual positive \(y_i = 1\) |
Actual negative \(y_i = 0\) |
|
Predicted positive \(\hat{y}_i = 1\) |
\(-C(1|1) = b_0 = \gamma \cdot (CLV - d - c) - (1 - \gamma) \cdot c\) |
\(C(1|0) = c_0 = -(d + c)\) |
Predicted negative \(\hat{y}_i = 0\) |
\(C(0|1) = c_1 = 0\) |
\(-C(0|0) = b_1 = 0\) |
Empulse already has metrics implemented that can handle this cost-benefit matrix. But you can easily implement your own cost-benefit matrix by passing the costs and benefits to the metrics and models.
1.1.3. Instance-dependent Costs#
So far all costs have been constant. However, in many real-world applications, the cost of classification can vary between instances. For instance, in the context of customer churn, the cost of misclassifying a highly valuable churner is higher than the cost of misclassifying a less valuable churner. To account for this, we can introduce instance-dependent costs. We can say that we take the individual customer’s lifetime value into account. The instance-dependent cost matrix is shown below.
Actual positive \(y_i = 1\) |
Actual negative \(y_i = 0\) |
|
Predicted positive \(\hat{y}_i = 1\) |
\(-C_i(1|1) = b_{0,i} = \gamma \cdot (CLV_i - d - c) - (1 - \gamma) \cdot c\) |
\(C_i(1|0) = c_{0,i} = -(d + c)\) |
Predicted negative \(\hat{y}_i = 0\) |
\(C_i(0|1) = c_{1,i} = 0\) |
\(-C_i(0|0) = b_{1,i} = 0\) |
In Empulse instance-dependent costs are represented as arrays.
These arrays are passed to the metrics and models as tp_cost, fp_cost, fn_cost, and tn_cost.
So note that if you pass a single value to these parameters, Empulse will interpret it as a class-dependent cost.
class-dependent cost:
tp_cost = 1
fp_cost = 1
fn_cost = 1
tn_cost = 1
instance-dependent cost:
tp_cost = [1, 2, 3, 4, 5]
fp_cost = [1, 2, 3, 4, 5]
fn_cost = [1, 2, 3, 4, 5]
tn_cost = [1, 2, 3, 4, 5]
1.1.4. Converting the cost-matrix to metrics#
As mentioned earlier, Empulse provides a variety of metrics to evaluate the performance of a model using the cost matrix. The section below dive into the details of the metrics and how they can be used to evaluate the performance of a model.
For a brief summary of what each metric does and why it is useful, see the table below.
Metric |
Description |
|---|---|
Measures how much a classifier would cost if it were to be used in the real world. It takes the instance-dependent costs into account. |
|
Similar to the cost loss, but takes the predicted class probabilities into account. So it will punish classifiers if they are not confident in their predictions. It takes the instance-dependent costs into account. |
|
Similar to the expected cost loss, but uses the logarithm of the predicted class probabilities. This will punish classifiers if they are not confident in their predictions and will punish them more if they are very confident in the wrong class. This can be seen as a generalization of the weighted cross-entropy loss. It takes the instance-dependent costs into account. |
|
Measures how much a classifier saved over a baseline model (in terms of the cost loss). 1 is the perfect model, 0 is as good as the baseline model, and negative values are worse than the baseline model. It takes the instance-dependent costs into account. |
|
Similar to the savings score, but takes the predicted class probabilities into account. So it will punish classifiers if they are not confident in their predictions. It takes the instance-dependent costs into account. |
|
Measures how much profit a classifier would make if it were to be used at the optimal decision threshold. The optimal decision threshold maximizes the profit and is calculated by the metric. It does NOT take the instance-dependent costs into account, rather it evaluates global classifier performance. |
|
Allows you to define your own cost-benefit or cost matrix and use it as a metric. You can define a maximum profit, expected cost and savings metric. Read more in Define your own cost-sensitive or value metric. |
1.1.4.1. (Expected) Cost Loss#
The cost loss measures what the cost of a classifier would be if it were to be used in the real world. Therefore, you want to pick a classifier that minimizes the cost loss.
The cost loss of a classifier with parameters \(\theta\) is the sum of the costs associated with the predicted classes. It is calculated as follows:
where \(\hat{y}_i\), \(y_i\), \(X_i\) are the predicted class, true class, and feature vector of the \(i\)-th instance, respectively.
The expected cost loss is the sum of the costs weighted with the predicted class probabilities.
where \(\text{P}(y_i| X_i, \theta)\) is the predicted class probability of the \(i\)-th instance.
1.1.4.2. (Expected) Savings Score#
The cost savings of a classifiers is the cost the classifier saved over a baseline classification model. By default, the baseline model is the naive model (predicting all ones or zeros whichever is better). With 1 being the perfect model, 0 being not better than the baseline model.
with \(\theta^\prime\) being the parameters of the baseline model. If the baseline model is the naive model, the cost savings can be calculated as follows:
The expected savings of a classifier is the expected cost the classifier saved over a baseline classification model.
Since the naive model only predicts 1s or 0s, the expected cost of the naive model is the same as the cost of the naive model.
1.1.4.3. (Expected) Maximum Profit Score#
The maximum profit score of a classifier measures how much profit a classifier would make if it were to be used at the optimal decision threshold. To maximize the profit, let’s define the profit as follows:
where \(F_0(t)\) and \(F_1(t)\) are the false positive and false negative rates at threshold \(t\), and \(\pi_0\) and \(\pi_1\) are the prior probabilities of the classes. Note that in value-driven literature, the positive class is denoted as 0 and the negative class as 1 (hence \(\pi_0\) is the prior probability of the positive class).
The optimal decision threshold \(T\) is the threshold that maximizes the profit. The maximum profit score is the profit at the optimal decision threshold.
In the the maximum profit score, it is assumed that the costs and benefits are deterministic. If you assume that the costs and benefits are stochastic, you can use the expected maximum profit score.
where \(w(b_0, c_0, b_1, c_1)\) is the join probability density function of the cost-benefit distribution. In practice usually only one variable is presumed to be stochastic.